

There has been a fair outrage from certain authors and bloggers who claim that my last piece about the Amazon Algorithm did not consider the way lists (often referred to by the author community as “poplists” although this is not an Amazon term) work. There has also been some whispering about BookBub’s sales being left out of Amazon results, and a high misunderstanding perpetuated by crowd mentality and myth online.
I called myself a “search expert” in the last post. Clarification: my entire adult working life has been spent in publishing, marketing, and search for multinational banks, automobiles, telecommunications – and books. I was responsible for multi-million-dollar accounts for multi-billion-dollar companies, who relied on my team to deliver conversions (sell stuff) globally, and I’ve been doing that for twenty years. For the last six of those years I have worked exclusively in editing and book marketing.
So let’s get down to cracking open a few of these nuts.
MYTH#1 – Amazon has many algorithms for the Bestseller Rank and Lists, and they are separate for sales and products
TRUTH – The A9 algorithm feeds many different variables and sorts these into lists and rank
Semantics are really off in the world of indie.

One algorithm feeding many lists that have many different variables, not many “algos.” Sometimes, people, even informed people, refer to these variables as “algorithms” plural. An algorithm is by definition a collective noun used to describe a set of instructions given to quantify data.
It’s more than one algorithm when it’s running a separate set of steps. So you might say Google and Amazon have different algorithms.
Variables.
What is the Amazon Algorithm?
Slide @TonyVerre, Amazon e-tailor expert from SMX 2016
The algorithm, the A9, spits out results in SERPs (Search Engine Results Pages). These SERPs are actually divided into lists on Amazon, which are Amazon’s way of presenting the data for users in the most enticing way for sales. Products are sorted for optimum sales. Not a separate one for products, and then sales. One algorithm using all sets of data. Because products and sales are intrinsic. Amazon want to use what sells well in its suggesters, and then serve them to users in a palatable list.
Dave Chesson, Kindle ranking expert at SEMRush says, “Like Google, A9 works to find the right pages using specific on-page and off-page data in order to build their own SERPs.”
What has become known as “Poplists” by indie authors on forums is the equivalent to SERPs on Google, the search pages that come up when looking in categories. However, these pages are generated with a different agenda: to not only study your buying behavior from what you browse, click, buy, wish for, and review, but also to forcibly suggest products you are most likely to buy by placing them right in front of your face during searches.
Comparing Google Search Results to Amazon Lists
After Amazon, now with 3 times the search traffic of Google for products, Google is the most well-used platform for search online worldwide. In the years I worked in the media search environment, vertical search came into play on Google.
Google is a different type of algorithm to Amazon in that it has a different objective: to serve you the most relevant results and learn from what you click and read what adverts to serve you to make money for themselves. They are obsequious in that they want to learn from your own decisions and what you look at. It’s an unstructured site, in other words it has no content to begin with, and does not attempt to catalogue information in any finite way.
Google uses lists too, by sorting into Books, Videos, Maps, etc. This is vertical search: Sorting results into piles for you to find the most relevant items:
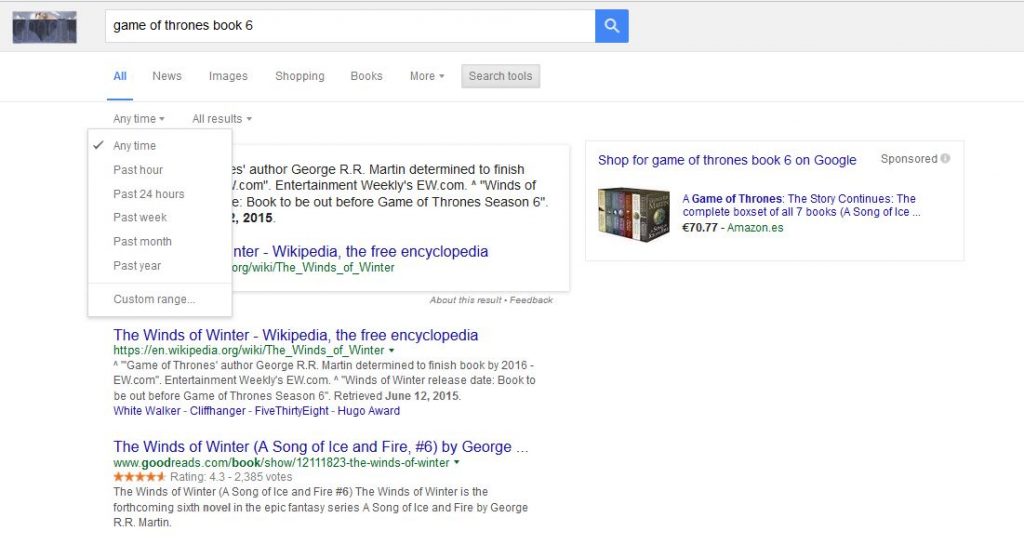
Or you can turn off personalization in Google to see the overall results not for just you:
Here’s an article about vertical search from Editor-in-Chief and SMM manager at WebCEO, Nelly Vinnik. She says, “Vertical Search returns specialized results which represent different types of content for a query. You can search for images in Image Search, for videos in Video Search, for news in News Search, and local shops or restaurants in Maps Search…” Sound a bit familiar if you replace the words for search with Category, Best Seller, Popular…”?
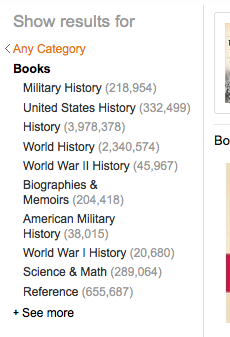
Here’s an Amazon’s category SERP (the proper name for the word “Poplist” bandied about) when I search for Epic Fantasy. I do buy GOT books, so it’s most relevant to me with “Most Relevant” set on the right, which is another variable, as a sortable list.

If a user logs into Amazon, their preferences, search history and everything they browsed and bought previously, along with everything people like them in demographic bought is fed into the algorithm. From the search bar input also, which is one part of the algorithm, Amazon then generates lists of products that the user would most likely buy. That is why my lists look different to my husband’s after searching for the same keyword, and also why products may be out of rank order on the page.
Personalization in Amazon
Unlike Google, personalization is set by default. As discussed in Part I, you could turn off some personalization, but you will end up with skewed results that won’t help you shop or rank your book because you are still tied to everyone else’s personalized results thrown in the mix, so you can only turn off 3rd party tracking.
These lists given are used to encourage you to buy products in the order you yourself are most likely to buy them, despite their rank. This is because unlike Google, which is used for research and finding things out, maps, and reading stuff on the web, Amazon is a shop. If you go to Amazon, you are at the very least thinking about making a purchase. This means Amazon has to present results that make you want to buy.
Lists – Vertical SERPs in Amazon
The Amazon algorithm is a set of instructions that sorts the catalogue of products into lists pertinent to that buyer’s personal choices including Rank, popular items, and Hot New Releases. These lists have different parameters and feed directly from the search and product information available at the time of the search. These lists are the exact same thing as vertical search in Google with Books, Maps, Videos etc. in the image above, but they sort data by different criteria.
Lists = Various ways of sorting and presenting products by criteria given for that variable
 There are many lists, such as:
There are many lists, such as:
- Best Seller Lists
- Popularity Lists
- Recently Tagged Lists
- Recently Popular Lists
- New Release Lists
- Movers and Shakers
- Hot New Releases
- 90-day New Releases
- Categories
The main lists that are caught up in myth-making are:
- Categories SERPs (Poplist) – Category-based filtering by sales in category + personalization
Shown above, filterable in many ways by category, sub-category, relevance etc. and will not be in ranking order necessarily
- Popular Items – Sales, ranking, personalization, plus timely Amazon choices (Seasonal etc.)
Popular Items are shown in a list of items selling well at that moment, and according to your own personalization results so Amazon can make you buy something more quickly. This list feeds off sales and personalization factors as shown in the last post I wrote and is also timely to make room for promotional timely products such as Easter, Xmas, new JK Rowling etc. - Hot New Releases – Sales in recent time against others in your category and Amazon choices
Hot New Releases shows results by how many books sold just released in the last 30-90 day and coming soons based on both preorder books and trad publisher dates. Also here Amazon adds the products it wants to show you that are going to be released, based or your personal history, because they are a shop, and they want to push products they have deals on – one factor myth-spreaders forget when second-guessing this stuff. We’ve seen authors promoted in a three-day push make this list pretty consistently, but you need to be selling around 30-50 books a day in a lower-volume subcategory to make this work so quickly. - Best Seller Rank – Sales but considers ranking factors also for driving sales
Rank is a straightforward sales result, but also takes into consideration all the factors I shared in the last post, because newsflash, Amazon wants to sell good products. So you can and will be dropped if your product does not meet quality or content guidelines – see below. Historically how you sold also counts towards keeping ranked, as does review recency and volume of reviews. *This is not “bestseller” as in books, but the best seller in the category, i.e. the seller/item that does best, and is used in all categories across Amazon, not just books.
MYTH#2 – It’s Possible For Authors To Test Amazon As A User To Find Patterns To Help With Ranking
TRUTH – While it’s possible to examine real-time data for immediate promotion, it’s absolutely impossible to use customer data over time to conclude anything that could help authors sell books
False Positive/Negative Results Done by Author Groups
As an author it is impossible – yes, I will say that again for certain critics among you – IMPOSSIBLE to garner the whole picture if you test using customer data. This is because you cannot second-guess the results shown in real time for every user on Amazon. It is akin to guessing everyone’s favorite color by knowing your own, and then assuming that people must like green because they don’t like blue. This sort of testing in software development is only used when QA managers (Quality Assurance) are trying to break software to prove that further testing is needed, and NOT to draw conclusions.
You can see why an unqualified person running tests may not be doing it right just by looking at the different types of testing qualified software testers use or here for the UK standards documentation. Like any experiment, the premise must be clean and infallible. When developing detection algorithms or tests, a balance must be chosen between risks of false negatives and false positives. Usually there is a threshold of how close a match to a given sample must be achieved before the algorithm reports a match. The higher this threshold, the more false negatives and the fewer false positives.
When data drawn from these sorts of moveable tests is given as proof of a function, false positives appear that in reality do not prove anything concrete. Just to clarify, this was part of my job for many years when project managing software development. These are the issues.
Problems with testing Amazon data from users’ searches and lists
- Real Time: Because Amazon is a collaborative filtering item to item algorithm, any data is volatile because it relies on customer and item grouping that changes in real time. Amazon builds tables of data that put similar customers and similar items in the same group to identify possible recommendations in advance of the search. Therefore testing over time will prove nothing due to promotions and additions all the time that immediately change the base data.
- Every user’s Experience is unique: This means any data gathered from testing varies wildly from person to person and item search to item search and becomes absolutely unique to each and every customer in real time. If any test were made and then repeated, data would vary wildly due to hourly updates of ranking, IP, and other factors. For instance, just to work out what Amazon will show in recommendations requires the entire data set, which nobody but Amazon has at their disposal (see diagram). Nobody on the planet has this data to work out anything this way, in a way not even Amazon, because it can only be calculated in real time by their own algorithm. See below for their own ML tool that gives you a chance to find stuff out behind the scenes.

Slide shows calculation made to show recommendations on Amazon in the algorithm, by Roger Chen, CIO at Eternal Sparkle Infocom Limited (HK)
- Sparsity of data: In reality a customer will buy very few books in relation to Amazon’s catalogue. Bear in mind that 1% of 2 million books is 20,000 books, and the average American reads 2 books a year! Therefore, data cannot be reliable because of its sparsity in relation to the test being carried out – basing data on just a few purchases does not give a reliable predictive set. The algorithm relies on memory-based historical purchases data and grouping customers by demographic to attempt to serve the best matches, but it’s obviously crazy to think any focus group testing would come up with any reliable data if even Amazon cannot.
- Scalability: As users purchase and join Amazon, the data changes. Data only stays fresh for one hour. After that, any data-based testing is wrong and old, and will change by the time a new test is conducted.
Averages Over Time Do Not Mean Clean Data
If anyone reckons they have tested the algorithm and beat it with focus group tests, they are misguided. Testers on author forums are not making progress because the data is wildly volatile, and the data is huge, inhumanly so. Given the predictive groups formed from less than the bare minimum of data needed to make a prediction is used in tests by authors, it’s impossible to draw an average or trend. Which is why we have to use what Amazon does give us to make sure your book exposure is the best it can be. In their study for the UK Government on quantifying data in instable and real-time algorithms Neil Johnson and Guannan Zhao note, “Computers can trade freely in real-time – but humans cannot.”
In that vein, I thought I would share one of their equations used to figure out averages in online trading algorithms, where just like Amazon, charts and lists are changing in real-time. I hope this demonstrates fully that any claims to have cracked the lists without considering variance and black/grey swan events (see Data Mining and Predictive Analysis by Colleen McCue for more) among all the other factors and their patterns are nothing but Horton Hears A Who results. Unless, of course, you are an expert in predictive data in real-time algorithm calculus, like those who work at Amazon. To think the “University of Life” has prepared indie authors to predict Amazon is laughable!
Example of calculus used for real time algorithms (like Amazon’s) to figure out averages over time (UK Government)
So What Can We Test on Amazon As Authors?
The only way that authors can test data is by looking at real-time sales, keywords, ranking, and marketing factors such as quality, reviews, and content to compete in categories when they are ready to publish, and ready to consider a change in listing of any kind to help sales.
Tools that can be helpful include (non-affiliate links):
- Kindle Spy – to figure out competitor keywords in real-time in a category
- Kindle’s own browse keywords guide – to make sure all your keywords and categories are the best they can be (bear in mind there are a ton of other non-BISAC categories available by asking for them)
- Rank Calculator – to gauge how many books are selling in a category
- Keyword tools such as keywordtool.io can give you ideas on what your audience may look for using generic keywords to help with placing your book on Amazon in the correct category for your content
- Amazon’s own Machine Learning tool (advanced) so that you can run your own parameters straight from Amazon’s data, “ML algorithms discover patterns in data and construct predictive models using these patterns. Then, you can use the models to make predictions on future data.”
MYTH #3 – Amazon’s Lists have bugs that don’t make sense
TRUTH – No they don’t, they are set like that for a reason
Often the product you just bought will be shown, just in case you want another one. This isn’t a “bug.”
Amazon rightly thinks that if you liked the product enough to search for the same keywords again, maybe you want to buy it again or for a friend. This is way more relevant for everyday items like face creams or panties for example, but they still do it.
Agile development expert Abraham Marín Pérez defines the terminology:
- The definition of a defect is that the software doesn’t behave as per the specification
- A change request is that it does what it’s mean to do as per the specification last implemented, but what the customer is asking for is new functionality.
Therefore this would not be a bug or defect. It’s a change request, or a feature requirement (depending on what model of project management Amazon uses) requested by a stakeholder when software or code is adapted at a stage in the future, called an iteration. Because Amazon has never done this change it must be more fruitful for them to leave this list variable alone and that it meets specifications requested. I already have the GOT boxset in the photo above, for example.
MYTH #4 – Amazon pulls books from BookBub campaigns out of ranking
TRUTH – Amazon pulls books that don’t meet their quality guidelines, especially hardcore sex or erotic books masquerading as Romance.
If a romance book is not showing up, it’s likely that the book has been flagged for use of genital or sexual words that are inappropriate to its category. Many authors have tried tricking category ranks by putting their book in a very narrow category that has zero to do with their book. If this happens, Amazon might just drop that book. However, Bookbub book promos are NOT pulled from Amazon ranking. I wrote and asked if they had any clue as to why this myth is out there. Here’s the reply:
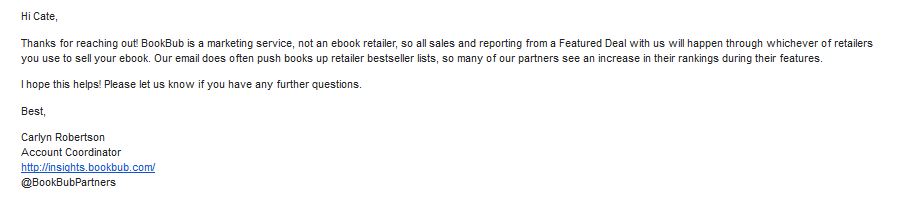
BookBub markets books to reader lists, the same way we do at SPR. Both companies send book ads to members of the public, who signed up for the newsletters and we do not have contact with the reviewers in any other way, so Amazon does not have an issue with it. Amazon loves books being advertised: it means they sell more books.
Bookbub do monitor books for quality and gatekeep to an extent, within their policy.
However, Amazon has manual procedures to drop books that do not meet guidelines and policy:
Your books and other content (such as book titles, cover art and product descriptions) must adhere to these content guidelines. We reserve the right to make judgments about whether content is appropriate and to choose not to offer it. We may also terminate your participation in the KDP program if you don’t adhere to these content guidelines.
Pornography
We don’t accept pornography or offensive depictions of graphic sexual acts.Offensive Content
What we deem offensive is probably about what you would expect.…
Poor Customer Experience
We don’t accept books that provide a poor customer experience. We reserve the right to determine whether content provides a poor customer experience. See the Guide to Kindle Content Quality for examples of content that’s typically disappointing to customers.
This means all my factors for success listed in my last post are absolutely essential to ranking and listing in Amazon SERPs. It matters to ranking, folks.
MYTH #5 – We will never know what Amazon does with its algorithm entirely
TRUTH – We will never know what Amazon does with its algorithm entirely
Authors often whine about Amazon’s dishonesty. In ALL of Amazon’s disclaimers, you are reminded that you are a seller using their absolutely free to set up platform to make money and that they are a private shop online with every right to demand you follow the rules they themselves made and asked you to follow when you signed up with them. Like a bratty kid with a wonderful bedroom and a brand new Apple iMac, authors make all sorts of claims about how Amazon are covering up information about how they sell. Well, of course they are! They are a private entity!
But having looked at all of Amazon’s documentation, everything you need to know is at your fingertips. Book success is possible with some effort and energy. Unfortunately it still stands you need a bloody good product and book page to make it. Maybe that’s the pill to swallow for most authors, and judging by some of the loudest offenders on forums, that lesson doesn’t seem to have hit home yet.
MYTH #6 – Reviews Are Not Counted Towards Ranking
TRUTH – Yes they are.
Here’s a screengrab from the A9 internal documentation, shared by CPC Strategy, a professional Amazon marketing company.

Phoenix Sullivan. That’s for you.
It is a FACT that you can lose ranking without customer reviews. Firstly, because of social proof as discussed in my last article – more reviews starred higher means more click-throughs to your Book Page, means more conversions, i.e. sales. Secondly, because Amazon will rank you lower than a competitor in a photo finish based on CTRs (click through rates) and review data.
Dave Chesson says, “If the Amazon search engine continues to place a particular product high in the SERPs based on just sales numbers, but customers aren’t leaving reviews or are leaving negative comments, Amazon will respond by lowering that product’s rankings and bring something else up further. While sales are important, Amazon cares about the customer experience as well.”
Not only that, since June 2015 Amazon’s overall star rating uses recency as a factor, so if you don’t spruce up reviews and sales, your book could start dropping in star value. Who wants 2 measly reviews next to their book listing? Not a lot of authors, is the answer. You can look at my article on how to get reviews safely and within Amazon policy here.
Yes, we are in the business of reviews at SPR, because provably time and again reviews, both customer and editorial, are incredibly important to market ANY product. I don’t think anyone with half a brain can argue with that if we’re going to sensibly look at the fundamentals of online product marketing.
In Conclusion
I am very disappointed that indie authors continue to turn to each other for advice instead of professionals, and aggressively naysay us when book professionals and technical advisors give free information that may help in an open and clarifying way.
I hope this post has taken the knowledge level down a notch into simpler terms for understanding, and that seeing Amazon lists and ranking as SERPs will increase author awareness and flag disinformation in the future, however entrenched in myth it may be.
As always, I have linked to verifiable results, sources, and facts of all working professional and scholarly experts cited, and thanks to all for your insights and materials used here.
Part I of this article can be read here.
Get an Editorial Review | Get Amazon Sales & Reviews | Get Edited | Get Beta Readers | Enter the SPR Book Awards | Other Marketing Services


















[…] Read Part II here. […]
Thanks for your GREAT post.
i am very much interest about “Amazon Algorithm” . i am searching and trying to learn this types of E commerce sites algorithm.
I am professional Amazon SEO expert. Work for keyword rank up by keyword search. i am waiting for more post about Amazon Algorithm.
Keep it up.
I will! It’s time to help authors. I am happy to spread knowledge to search professionals to bolster our industry and create great products for authors so they have successful books instead of ones that don’t sell.
[…] sent these two links on how Amazon works, so I thought I’d share them with you: part 1 and part 2. Now I better send out that prize for the Blog […]
Fantastic again. Sorry you had to defend your knowledge to morons.
Glad to be of service, Charlie.
It still blows my mind when I’m reading a really good article by someone who I don’t know personally and then all-of-a-sudden, I see my name…haha. Virtual High Five Cate. Then later on I saw my KDP Calculator listed – double virtual High Five!
In all seriousness, amazing post. I’ve been working with the Amazon API for my next software and just getting into the how the data is presented has been a real eye-opener. Like here’s a fun fact: Amazon doesn’t look at the title and subtitle as two separate entities…the way it pulls data it makes them inseparable. Based off of that, it leads me to believe that having your keyword in the subtitle is just as good as having it in the Title – but of course i can’t be sure.
Also, LOVED how you brought up the “node” aspect of the search engine. I’ve been fighting with people over that for a while. Many state that the words in your description aren’t tracked by A9. They’ll “disprove” it by copying a sentence and pasting it into the search bar. However, the algo doesn’t work in sentences. It works in batch parameters and this is highlighted by looking at the top of the SERP where, in the case of the person’s sentence search, Amazon suggests particular words from the sentence and crosses off the “of” “is” “the” etc…
Anyways, amazing article, great research and approach and kudos for the guts of writing this.
Thanks, Dave! I’m probably branded for life by the aforesaid “morons” cited above as a “revolutionary” at this point, but never mind. I know I can be trusted! I feel you are one of the professionals in a sea of amateurs. There’s not many around in this industry, so we have to support each other! Maybe one day we can do a super-podcast or something. As Chomsky once pointed out in the New York Review of Books, intellectuals are responsible for the searching of truth and the exposure of lies. I’m fine with that. Hacks are ripping authors off to make money. It’s time to get busy – and noisy about what’s right and what’s not. Books are too important.
This is a great post full of useful info, but I have one question concerning the search autocomplete for keywords. I use this method with a separate browser perpetually set to private mode without being logged in to Amazon. My thinking was that this method would eliminate my personal history influence from the results. I’m not a tech or numbers guy, so I’m wondering if I was way off track. Thanks again for a great post.
I don’t think it would make a difference because you are forgetting the fact that Amazon is still taking into account the real time activity by other customers and those around you in your area. You would still have an IP address etc. It’s not just about your activity, and as soon as you type anything in that box, Amazon starts calculating what your needs are.
I’m assuming they can weight certain factors in the algorithm, is that true? For instance, they can give a higher ranking to books in their KU programme for best seller lists. Is that true? It’s certainly looking that way.
If you mean books that sell more and are more recently read, yes, books can get weighed higher.
A fantastic article. Usually when i read about “Amazon Algorithms” my brain dies a death and my eyes gloss over. However, I stayed for the whole article. Clear and concise!
[…] Mythbusting the Amazon Algorithm: PART II […]
[…] highly recommend reading Baum’s full article. She even wrote a Part II since part one was so well received. Thank you to @AssaphMehr for bringing this to my […]
Are you available for hire? LOL, I bet I couldn’t afford your fees. Thanks for the extremely helpful information. I’m going to pour a dram and try to make sense of it all. Then, God willing, try to apply it to my books on amazon.
Thank you,
chris
Yes, actually! Feel free to contact me at any time for a custom quote!
[…] Read Part II here. […]
[…] can read Part I and II of this series […]
Two great articles. Thank you. Don’t know how I missed them until now. Can you tell us how KENPages read are used vis-a-vis sales in the algorithm? I have a feeling that ratings are weighted toward KENP.
Wow that’s a good question that might actually deserve a whole other post! I don’t think it’s vis-a-vis as you say. These are all factors going into the same pot for ranking, not competing figures. However, a borrow in itself does not count as a verified transaction. A KU download is NOT counted as a sale. So given that ranking is relative to all the other books on Amazon, pages read may help Amazon decide which book goes where in ranking on a photo-finish, but I’m not convinced yet that pages read adds up to much of a jump in ranking overall, and is instead another factor of many. I cannot see that if your book is borrowed and never finished, that that looks good in “algorithm speak” – that is, if you keep getting 10% read but never 100% the algorithm sees 90% of the book is rejected. Algorithms look for patterns after all. But I think I can say with some certainty that KENP would not be an overriding factor in ranking against pure sales and clear profit for Amazon. Given a page read is worth (more or less – per month fluctuates) $0.005, and your pages read over the month are 450, you only get $2.25 per month before royalty cuts. This could be any time after the reader downloads the book. This is really not a surefire way of measuring a book’s impact on the market, so I’m not convinced for that reason it’s a different set of data, except to furnish the KENP table in your book admin! Hope my answer is not as clear as mud!
Hi Cate. Interesting answer. I’m wondering if you’re right, though, because I noticed an improvement in my books’ rankings when I placed them in KDP select and the books that have higher numbers of KENP are better rated. If your book has (let’s say) 450 KENPages and KU reports 45,000 pages read, surely that has to represent the equivalent of 100 books read, whether or not some of the readers stopped after 10%. Also,my observations have suggested that 100 books sold + the equivalent of (say) 40 read using KU, seem to rate higher than 140 books sold that are not included in KDP select. This suggests a built-in bias in the rating system toward KDP select (which would seem to make sense, as Amazon is keen to get as many books as possible into KDP select).
I think it’s relative to all books on Amazon, that’s what I was saying. So it’s another part of the algorithm, another factor. The point I was making is that if it’s the same 450 pages, i.e. the first 10%, as the algorithm definitely tracks patterns, it could be that in some circumstances, considering the numbers are cut into all kinds of different ways to produce lists, it is possible it could affect you negatively too. I think if you have 100 books with every page read, then that obviously would be a plus, but I have to assume it would be less positive if the book keeps being abandoned. Luckily we have a lab of sorts here. We’ll do some live tracking with this and I’ll get back to you!
Okay, now I understand what you meant. It seems unlikely that a book would be repeatedly abandoned after a few pages read, and if this did happen, I would expect that book simply to wither and die. So, I would have thought it unnecessary of the algorithm to track that sort of negative reader reaction, and just plug the KNEPages into the positive side of the rating algorithm. I’d be interested in what your lab comes up with. 🙂
Today I requested some tests! More soon, hopefully!
Thank you so much for clearing up so many myths that I have been reading lately. This has been the best and most informative post I’ve read since I started preparing for my own book launch.
There is one question that I was looking for and didn’t see the answer. If I have several smaller books (read, short stories) posted on amazon and they haven’t sold any copies in years, will it increase my author ranking to unpublish them?
[…] Mythbusting 2- Amazon Lists and Sales […]
[…] parts of this series: I II […]
[…] 1 | Mythbusting 2 | Mythbusting 3 |Mythbusting 4| Mythbusting […]